
AI Informations and News
- 202104 EfficientNetV2: Smaller Models and Faster Training (2021.4)
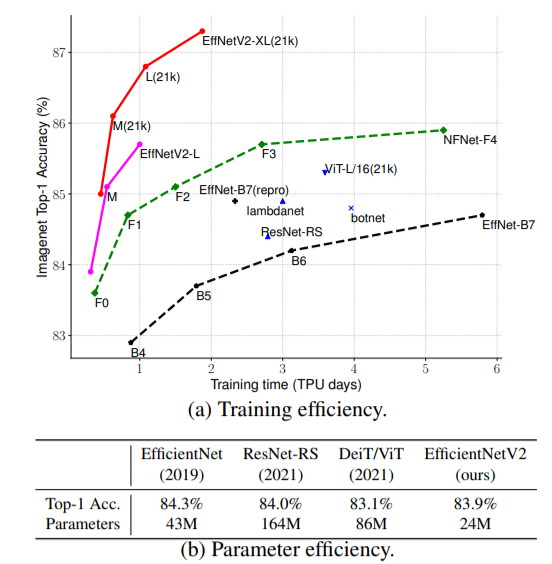
이전 모델보다 더 빠른 훈련 속도와 더 나은 매개 변수 효율성을 제공하는 새로운 컨볼 루션 네트워크 군인 EfficientNetV2를 소개합니다. 이 모델 군을 개발하기 위해 학습 인식 신경 아키텍처 검색 및 확장을 조합하여 학습 속도와 매개 변수 효율성을 공동으로 최적화합니다. 모델은 Fused-MBConv와 같은 새로운 작업으로 강화 된 검색 공간에서 검색되었습니다. 우리의 실험에 따르면 EfficientNetV2 모델은 최첨단 모델보다 훨씬 빠르게 학습하는 동시에 최대 6.8 배 더 작습니다. 훈련 중에 이미지 크기를 점진적으로 늘려서 훈련 속도를 더 높일 수 있지만 종종 정확도가 떨어집니다. 이러한 정확도 저하를 보상하기 위해 우리는 이미지 크기와 함께 정규화 (예 : 드롭 아웃 및 데이터 증가)를 적응 적으로 조정하는 향상된 점진적 학습 방법을 제안합니다. 점진적 학습을 통해 EfficientNetV2는 ImageNet 및 CIFAR / Cars / Flowers 데이터 세트에서 이전 모델을 훨씬 능가합니다. 동일한 ImageNet21k에 대한 사전 교육을 통해 EfficientNetV2는 ImageNet ILSVRC2012에서 87.3 % top-1 정확도를 달성하여 동일한 컴퓨팅 리소스를 사용하여 5 배 -11 배 빠르게 교육하면서 최근 ViT보다 2.0 % 정확도를 능가합니다. https://arxiv.org/pdf/2104.00298v1.pdf
- 20210331 ResNet-RS (wonwizard)
최근 21년 3월에 나와 구글에서 나온 논문 ResNet-RS 가 주목받고 있다고 합니다. (논문 원제 : Revisiting ResNets: Improved Training and Scaling Strategies) 성능향상보다 속도를 비판하며 ResNet-RS는 EfficientNets보다 1.7 배-2.7 배 빠르면서 ImageNet에서 비슷한 정확도를 달성했다고 함.
ResNet-RS에서 RS는 re-scaled로 EfficientNet의 Scaling기법을 수정하여 overfitting을 유발하는 width보다 depth를 키우는 방식을 선택하고 resolution scaling을 더 천천히 해야한다고 주장.
요새 논문들이 기존 EfficientNet 를 비판하면서 제시되는 두 줄기가 Transformer 구조로 가거나 다시 ResNet 들 로 돌아가서 Dense 한 연산 구조를 노력하는 것이라고 하며 이 논문은 후자의 경우.
이 논문에서 구글 저작들이 과감히 아래처럼 주장.
“당신은 Efficientnet 이 필요하지 않다. 실무자들은 이러한 간단한 수정된 ResNet을 향후 연구를 위한 기준으로 사용하는 것을 추천합니다.”
https://arxiv.org/pdf/2103.07579.pdf
- 2021.2.18 Transformers in Vision: A Survey
https://arxiv.org/abs/2101.01169 Transformer 소개 & Transformers for Image Recognition https://hoya012.github.io/blog/Vision-Transformer-1/ 2021.2.18 자연어 처리(NLP)에서 압도적인 성능을 보여주며 주류로 자리잡은 Transformers 모델을 컴퓨터 비전에 적용하려는 시도들을 정리한 서베이 논문인 “Transformers in Vision: A Survey” 를 읽고 간단히 정리
- 2021.1.7 오픈AI는 GPT-3가 언어를 생성하듯 이미지를 만들어내는 DALL·E 모델 공개.
기존 이미지 생성 기술과 달리 각 이미지 데이터를 큐레이팅, 라벨링하는 것이 아니라 인터넷상에서 수집한 방대한 이미지와 이를 묘사한 캡션들 사용. 경험한 적이 없는 이미지도 새로 만들어.
http://www.aitimes.com/news/articleView.html?idxno=135460
오픈AI, 글 쓰는 GPT-3에서 진화… 텍스트 읽고 그림 그리는 AI 모델 ‘DALL·E’ 및 ‘CLIP’ 공개
컴퓨터 비전과 자연어처리(NLP) 기술을 결합해, 제시된 텍스트를 인식해 이미지를 생성하고 이미지를 각각 카테고리로 분류할 수 있는 두 가지 새로운 AI 모델…
https://www.aitimes.kr/news/articleView.html?idxno=18892
- 2021년 이전 것은 이전 글에